Используем малоизвестные функции Google, чтобы найти сокрытое. Удаляем лишний мусор компьютера вручную
Язык запросов - это искусственно созданный язык программирования, используемый для того, чтобы делать запросы в базах данных и информационных системах.
В целом, такие способы запросов можно классифицировать в зависимости от того, служат они для базы данных или для поиска информации. Разница в том, что запросы к подобным сервисам совершаются для получения фактических ответов на поставленные вопросы, в то время как поисковая система пытается найти документы, содержащие сведения, относящиеся к интересующей пользователя области.
Базы данных
Языки запросов по базам данных включают в себя следующие примеры:
- QL - объектно-ориентированный, относится к преемник Datalog.
- Контекстный (CQL) - формальный язык представления запросов для информационно-поисковых систем (таких, как веб-индексы или библиографические каталоги).
- CQLF (CODYASYL) - для CODASYL-TYPE баз данных.
- Концепт-ориентированный язык запросов (COQL) - используется в соответствующих моделях (com). Он основан на принципах моделирования данных construpt и использует такие операции, как проекция и де-проекция многомерного анализа, аналитические операции и выводы.
- DMX - используется к моделям
- Datalog - это язык запросов к дедуктивным базам данных.
- Gellish English - это язык, который может использоваться для запросов в базы данных Gellish English и позволяет вести диалоги (запросы и ответы), а также служит для информационного моделирования знаний.
- HTSQL - переводит http-запросы на SQL.
- ISBL - используется для PRTV (одной из первых реляционных систем управления базами данных).
- LDAP - это протокол для запросов и служб каталогов, работающий по протоколу TCP/IP.
- MDX - необходим для баз данных OLAP.

Поисковые системы
Язык поисковых запросов, в свою очередь, направлен на нахождение данных в поисковых системах. Он отличается тем, что часто запросы содержат обычный текст или гипертекст с дополнительным синтаксисом (например, «и»/«или»). Он значительно отличается от стандартных подобных языков, которые регулируются строгими правилами синтаксиса команд или содержат позиционные параметры.
Как классифицируются поисковые запросы?
Существует три широких категории, которые охватывают большинство поисковых запросов: информационная, навигационная и транзакционная. Хотя эта классификация не была закреплена теоретически, эмпирически она подтверждена наличием фактических запросов в поисковых системах.
Информационные запросы - это те, которые охватывают широкие темы (например, какой-либо определенный город или модель грузовиков), в отношении которых может быть получено тысячи релевантных результатов.
Навигационные - это запросы, которые ищут один сайт или веб-страницу на определенную тему (например, YouTube).

Транзакционные - отражают намерение пользователя выполнить определенное действие, например, совершить покупку автомобиля или забронировать билет.
Поисковые системы часто поддерживают четвертый тип запроса, который используется намного реже. Это так называемые запросы подключения, содержащие отчет о связности проиндексированного веб-графика (количество ссылок на определенный URL, или сколько страниц проиндексировано с определенного домена).
Как совершается поиск информации?
Стали известны интересные характеристики, касающиеся веб-поиска:
Средняя длина поискового запроса составляла 2,4 слов.
- Около половины пользователей направляли один запрос, а чуть меньше трети пользователей делали три или более уникальных запросов один за одним.
- Почти половина пользователей просматривала только первые одну-две страницы полученных результатов.
- Менее 5% пользователей используют расширенные возможности поиска (например, выбор каких-либо определенных категорий или поиска в поиске).
Особенности пользовательских действий
Исследование также показало, что 19% запросов содержали географический термин (например, названия, почтовые индексы, географические объекты и т. д.). Еще стоит отметить, что помимо коротких запросов (то есть с несколькими условиями), часто присутствовали и предсказуемые схемы, по которым пользователи меняли свои поисковые фразы.

Также было установлено, что 33% запросов от одного пользователя повторяются, и в 87% случаев юзер будет нажимать на тот же результат. Это говорит о том, что многие пользователи используют повторные запросы, чтобы пересмотреть или заново найти информацию.
Частотные распределения запросов
Кроме того, специалистами было подтверждено, что частотные распределения запросов соответствуют степенному закону. То есть небольшая часть ключевых слов наблюдается в самом большом списке запросов (например, более 100 млн), и они наиболее часто используются. Остальные же фразы в рамках тех же тематик применяются реже и более индивидуально. Это явление получило название принципа Парето (или «правило 80-20»), и оно позволило поисковикам использовать такие методы оптимизации, как индексирование или разбиение базы данных, кэширование и упреждающую загрузку, а также дало возможность совершенствовать язык запросов поисковой системы.
В последние годы было выявлено, что средняя длина запросов неуклонно растет с течением времени. Так, среднестатистический запрос на английском языке стал длиннее. В этой связи компания Google внедрила обновление под названием «Колибри» (в августе 2013 года), которое способно обрабатывать длинные поисковые фразы с непротокольным, «разговорным» языком запроса (наподобие «где ближайшая кофейня?»).

Для более длинных запросов используется их обработка - они разбиваются на фразы, сформулированные стандартным языком, и выводятся ответы на разные части по отдельности.
Структурированные запросы
Поисковые системы, поддерживающие и синтаксис, используют более расширенные языки запроса. Пользователь, который ищет документы, охватывающие несколько тем или граней, может описывать каждую из них по логической характеристике слова. По своей сути, логический язык запросов представляет собой совокупность определенных фраз и знаков препинания.
Что такое расширенный поиск?
Язык запросов «Яндекса» и «Гугла» способен осуществлять более узконаправленный поиск при соблюдении определенных условий. Расширенный поиск может искать по части названия страницы или префиксу заголовка, а также в определенных категориях и перечнях имен. Он также может ограничить поиск страниц, содержащих определенные слова в названии или находящихся в определенных тематических группах. При правильном использовании языка запросов он может обрабатывать параметры на порядок более сложные, чем поверхностные результаты выдачи большинства поисковых систем, в том числе по заданным пользователем словам с переменным окончанием и похожим написанием. При представлении результатов расширенного поиска будет отображена ссылка на соответствующие разделы страницы.

Также это возможность поиска всех страниц, содержащих определенную фразу, в то время как при стандартном запросе поисковые системы не могут остановиться на любой странице обсуждения. Во многих случаях язык запросов может привести на любую страницу, расположенную в тегах noindex.
В некоторых случаях правильно сформированный запрос позволяет найти информацию, содержащую ряд специальных символов и букв других алфавитов (китайские иероглифы например).
Как читаются символы языка запросов?
Верхний и нижний регистр, а также некоторые (умляуты и акценты) не учитываются в поисках. Например, поиск по ключевому слову Citroen не найдет страницы, содержащие слово «Цитроён». Но некоторые лигатуры соответствуют отдельным буквам. Например, поиск по слову «аероскобинг» легко найдет страницы, содержащие «Эрескебинг» (АЭ = Æ).
Многие не алфавитно-цифровые символы постоянно игнорируются. Например, невозможно найти информацию по запросу, содержащему строку |L| (буква между двумя вертикальными полосами), несмотря на то что этот символ используется в некоторых шаблонах конвертирования. В результатах будут только данные с «ЛТ». Некоторые символы и фразы обрабатываются по-разному: запрос «кредит (Финансы)» отобразит статьи со словами «кредит» и «финансы», игнорируя скобки, даже если и существует статья с точным названием «кредит (Финансы)».

Существует множество функций, которые можно использовать с применением языка запросов.
Синтаксис
Язык запросов «Яндекса» и «Гугла» может использовать некоторые знаки препинания для уточнения поиска. В качестве примера можно привести фигурные скобки - {{поиск}}. Фраза, заключенная в них, будет подвергаться поиску целиком, без изменений.
Фраза в позволяет определиться с объектом поиска. Например, слово в кавычках будет распознаваться как используемое в переносном смысле или как вымышленный персонаж, без кавычек - как информация более документального характера.
Кроме того, все основные поисковые системы поддерживают символ «-» для логического «не», а также и/или. Исключение - термины, которые не могут быть разделены с помощью префикса дефисом или тире.
Неточное соответствие поисковой фразы отмечается символом ~. Например, если вы не помните точную формулировку термина или названия, вы можете указать ее в строке поиска с указанным символом, и сможете получить результаты, имеющие максимальное сходство.
Параметры специализированного поиска
Существуют и такие параметры поиска, как intitle, и incategory. Они представляют собой фильтры, отображаемые через двоеточие, в виде «фильтр: строка запроса». Строка запроса может содержать искомый термин или фразу, или же часть либо полное название страницы.
Функция «intitle: запрос» отдает приоритет в поисковой выдаче по названию, но также показывает и обычные результаты по содержанию заголовка. Несколько таких фильтров могут быть использованы одновременно. Как же использовать эту возможность?
Запрос вида «intitle: название аэропорта» выдаст все статьи, содержащие в заголовке название аэропорта. Если же сформулировать его как «парковка intitle: название аэропорта», то вы получите статьи с названием аэропорта в заголовке и с упоминанием парковки в тексте.
Поиск по фильтру «incategory: Категория» работает по принципу первоначальной выдачи статей, принадлежащих к определенной группе или списку страниц. Например, поисковой запрос по типу «Храмы incategory: История» будет выдавать результаты на тему истории храмов. Эту функцию также можно использовать как расширенную, задавая различные параметры.
А сегодня я расскажу еще про один поисковик, который используется пентестерами / хакерами — Google, точнее о скрытых возможностях Google.
Что такое гугл дорки?
Google Dork или Google Dork Queries (GDQ) — это набор запросов для выявления грубейших дыр в безопасности. Всего, что должным образом не спрятано от поисковых роботов.
Для краткости такие запросы называют гугл дорки или просто дорками, как и тех админов, чьи ресурсы удалось взломать с помощью GDQ.
Операторы Google
Для начала я хотел бы привести небольшой список полезных команд Google. Среди всех команд расширенного поиска Гугл нас интересуют главным образом вот эти четыре:
- site - искать по конкретному сайту;
- inurl - указать на то, что искомые слова должны быть частью адреса страницы / сайта;
- intitle - оператор поиска в заголовке самой страниц;
- ext или filetype - поиск файлов конкретного типа по расширению.
Также при создании Дорка надо знать несколько важных операторов, которые задаются спецсимволами.
- | - оператор OR он же вертикальный слеш (логическое или) указывает, что нужно отобразить результаты, содержащие хотя бы одно из слов, перечисленных в запросе.
- «» - оператор кавычки указывает на поиск точного соответствия.
- — - оператор минус используется для исключения из выдачи результатов с указанными после минуса словами.
- * - оператор звездочка, или астериск используют в качестве маски и означает «что угодно».
Где найти Гугл Дорки
Самые интересные дорки — свежие, а самые свежие — те, которые пентестер нашел сам. Правда, если слишком увлечетесь экспериментами, вас забанят в Google… до ввода капчи.
Если не хватает фантазии, можно попробовать найти свежие дорки в сети. Лучший сайт для поиска дорков — это Exploit-DB.
Онлайн-сервис Exploit-DB — это некоммерческий проект Offensive Security. Если кто не в курсе, данная компания занимается обучением в области информационной безопасности, а также предоставляет услуги пентеста (тестирования на проникновение).
База данных Exploit-DB насчитывает огромное количество дорков и уязвимостей. Для поиска дорков зайдите на сайт и перейдите на вкладку «Google Hacking Database».
База обновляется ежедневно. На верху вы можете найти последние добавления. С левой стороны дата добавления дорка, название и категория.
 Сайт Exploit-DB
Сайт Exploit-DB В нижней части вы найдете дорки отсортированные по категориям.
 Сайт Exploit-DB
Сайт Exploit-DB  Сайт Exploit-DB
Сайт Exploit-DB Еще один неплохой сайт — это . Там зачастую можно найти интересные, новые дорки, которые не всегда попадают на Exploit-DB.
Примеры использования Google Dorks
Вот примеры дорков. Экспериментируя с дорками, не забудьте про дисклеймер!
Данный материал носит информационный характер. Он адресован специалистам в области информационной безопасности и тем, кто собирается ими стать. Изложенная в статье информация предоставлена исключительно в ознакомительных целях. Ни редакция сайта www.сайт ни автор публикации не несут никакой ответственности за любой вред нанесенный материалом этой статьи.
Дорки для поиска проблем сайтов
Иногда бывает полезно изучить структуру сайта, получив список файлов на нем. Если сайт сделан на движке WordPress, то файл repair.php хранит названия других PHP-скриптов.
Тег inurl сообщает Google, что искать надо по первому слову в теле ссылки. Если бы мы написали allinurl, то поиск происходил бы по всему телу ссылки, а поисковая выдача была бы более замусоренной. Поэтому достаточно сделать запрос такого вида:
inurl:/maint/repair.php?repair=1
В результате вы получите список сайтов на WP, у которых можно посмотреть структуру через repair.php.
 Изучаем структуру сайта на WP
Изучаем структуру сайта на WP Массу проблем администраторам доставляет WordPress с незамеченными ошибками в конфигурации. Из открытого лога можно узнать как минимум названия скриптов и загруженных файлов.
inurl:"wp-content/uploads/file-manager/log.txt"
В нашем эксперименте простейший запрос позволил найти в логе прямую ссылку на бэкап и скачать его.
 Находим ценную инфу в логах WP
Находим ценную инфу в логах WP Много ценной информации можно выудить из логов. Достаточно знать, как они выглядят и чем отличаются от массы других файлов. Например, опенсорсный интерфейс для БД под названием pgAdmin создает служебный файл pgadmin.log. В нем часто содержатся имена пользователей, названия колонок базы данных, внутренние адреса и подобное.
Находится лог элементарным запросом:
ext:log inurl:"/pgadmin"
Бытует мнение, что открытый код - это безопасный код. Однако сама по себе открытость исходников означает лишь возможность исследовать их, и цели таких изысканий далеко не всегда благие.
К примеру, среди фреймворков для разработки веб-приложений популярен Symfony Standard Edition. При развертывании он автоматически создает в каталоге /app/config/ файл parameters.yml, где сохраняет название базы данных, а также логин и пароль.
Найти этот файл можно следующим запросом:
inurl:app/config/ intext:parameters.yml intitle:index.of
 ф Еще один файл с паролями
ф Еще один файл с паролями Конечно, затем пароль могли сменить, но чаще всего он остается таким, каким был задан еще на этапе развертывания.
Опенсорсная утилита UniFi API browser tool все чаще используется в корпоративной среде. Она применяется для управления сегментами беспроводных сетей, созданных по принципу «бесшовного Wi-Fi». То есть в схеме развертывания сети предприятия, в которой множество точек доступа управляются с единого контроллера.
Утилита предназначена для отображения данных, запрашиваемых через Ubiquiti’s UniFi Controller API. С ее помощью легко просматривать статистику, информацию о подключенных клиентах и прочие сведения о работе сервера через API UniFi.
Разработчик честно предупреждает: «Please do keep in mind this tool exposes A LOT OF the information available in your controller, so you should somehow restrict access to it! There are no security controls built into the tool…». Но кажется, многие не воспринимают эти предупреждения всерьез.
Зная об этой особенности и задав еще один специфический запрос, вы увидите массу служебных данных, в том числе ключи приложений и парольные фразы.
inurl:"/api/index.php" intitle:UniFi
Общее правило поиска: сначала определяем наиболее специфические слова, характеризующие выбранную цель. Если это лог-файл, то что его отличает от прочих логов? Если это файл с паролями, то где и в каком виде они могут храниться? Слова-маркеры всегда находятся в каком-то определенном месте - например, в заголовке веб-страницы или ее адресе. Ограничивая область поиска и задавая точные маркеры, вы получите сырую поисковую выдачу. Затем чистите ее от мусора, уточняя запрос.
Дорки для поиска открытых NAS
Домашние и офисные сетевые хранилища нынче популярны. Функцию NAS поддерживают многие внешние диски и роутеры. Большинство их владельцев не заморачиваются с защитой и даже не меняют дефолтные пароли вроде admin/admin. Найти популярные NAS можно по типовым заголовкам их веб-страниц. Например, запрос:
intitle:"Welcome to QNAP Turbo NAS"
выдаст список айпишников NAS производства QNAP. Останется лишь найти среди них слабозащищенный.
Облачный сервис QNAP (как и многие другие) имеет функцию предоставления общего доступа к файлам по закрытой ссылке. Проблема в том, что она не такая уж закрытая.
inurl:share.cgi?ssid=
 Находим расшаренные файлы
Находим расшаренные файлы Этот нехитрый запрос показывает файлы, расшаренные через облако QNAP. Их можно просмотреть прямо из браузера или скачать для более детального ознакомления.
Дорки для поиска IP-камер, медиасерверов и веб-админкок
Помимо NAS, с помощью продвинутых запросов к Google можно найти массу других сетевых устройств с управлением через веб-интерфейс.
Наиболее часто для этого используются сценарии CGI, поэтому файл main.cgi - перспективная цель. Однако встретиться он может где угодно, поэтому запрос лучше уточнить.
Например, добавив к нему типовой вызов?next_file. В итоге получим дорк вида:
inurl:"img/main.cgi?next_file"
Помимо камер, подобным образом находятся медиасерверы, открытые для всех и каждого. Особенно это касается серверов Twonky производства Lynx Technology. У них весьма узнаваемое имя и дефолтный порт 9000.
Для более чистой поисковой выдачи номер порта лучше указать в URL и исключить его из текстовой части веб-страниц. Запрос приобретает вид
intitle:"twonky server" inurl:"9000" -intext:"9000"
 Видеотека по годам
Видеотека по годам Обычно Twonky-сервер - это огромная медиатека, расшаривающая контент через UPnP. Авторизация на них часто отключена «для удобства».
Дорки для поиска уязвимостей
Большие данные сейчас на слуху: считается, что, если к чему угодно добавить Big Data, оно волшебным образом станет работать лучше. В реальности настоящих специалистов по этой теме очень мало, а при дефолтной конфигурации большие данные приводят к большим уязвимостям.
Hadoop - один из простейших способов скомпрометировать тера- и даже петабайты данных. Эта платформа с открытым исходным кодом содержит известные заголовки, номера портов и служебных страниц, по которым просто отыскать управляемые ей ноды.
intitle:"Namenode information" AND inurl:":50070/dfshealth.html"
 Big Data? Big vulnerabilities!
Big Data? Big vulnerabilities! Таким запросом с конкатенацией мы получаем поисковую выдачу со списком уязвимых систем на базе Hadoop. Можно прямо из браузера погулять по файловой системе HDFS и скачать любой файл.
Гугл Дорки — это мощный инструмент любого пентестера, о котором должен знать не только специалист в области информационной безопасности, но и обычный пользователь сети.
Поисковая система Google (www.google.com) предоставляет множество возможностей для поиска. Все эти возможности – неоценимый инструмент поиска для пользователя впервые попавшего в Интернет и в то же время еще более мощное оружие вторжения и разрушения в руках людей с злыми намерениями, включая не только хакеров, но и некомпьютерных преступников и даже террористов.
(9475 просмотров за 1 неделю)
Денис Батранков
denisNOSPAMixi.ru
Внимание: Эта статья не руководство к действию. Эта статья написана для Вас, администраторы WEB серверов, чтобы у Вас пропало ложное ощущение, что Вы в безопасности, и Вы, наконец, поняли коварность этого метода получения информации и взялись за защиту своего сайта.
Введение
Я, например, за 0.14 секунд нашел 1670 страниц!
2. Введем другую строку, например:
inurl:"auth_user_file.txt"немного меньше, но этого уже достаточно для свободного скачивания и для подбора паролей (при помощи того же John The Ripper). Ниже я приведу еще ряд примеров.
Итак, Вам надо осознать, что поисковая машина Google посетила большинство из сайтов Интернет и сохранила в кэше информацию, содержащуюся на них. Эта кэшированная информация позволяет получить информацию о сайте и о содержимом сайта без прямого подключения к сайту, лишь копаясь в той информации, которая хранится внутри Google. Причем, если информация на сайте уже недоступна, то информация в кэше еще, возможно, сохранилась. Все что нужно для этого метода: знать некоторые ключевые слова Google. Этот технический прием называется Google Hacking.
Впервые информация о Google Hacking появилась на рассылке Bugtruck еще 3 года назад. В 2001 году эта тема была поднята одним французским студентом. Вот ссылка на это письмо http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html . В нем приведены первые примеры таких запросов:
1) Index of /admin
2) Index of /password
3) Index of /mail
4) Index of / +banques +filetype:xls (for france...)
5) Index of / +passwd
6) Index of / password.txt
Нашумела эта тема в англо-читающей части Интернета совершенно недавно: после статьи Johnny Long вышедшей 7 мая 2004 года. Для более полного изучения Google Hacking советую зайти на сайт этого автора http://johnny.ihackstuff.com . В этой статье я лишь хочу ввести вас в курс дела.
Кем это может быть использовано:
- Журналисты, шпионы и все те люди, кто любит совать нос не в свои дела, могут использовать это для поиска компромата.
- Хакеры, разыскивающие подходящие цели для взлома.
Как работает Google.
Для продолжения разговора напомню некоторые из ключевых слов, используемых в запросах Google.
Поиск при помощи знака +
Google исключает из поиска неважные, по его мнению, слова. Например вопросительные слова, предлоги и артикли в английском языке: например are, of, where. В русском языке Google, похоже, все слова считает важными. Если слово исключается из поиска, то Google пишет об этом. Чтобы Google начал искать страницы с этими словами перед ними нужно добавить знак + без пробела перед словом. Например:
ace +of base
Поиск при помощи знака –
Если Google находит большое количество станиц, из которых необходимо исключить страницы с определенной тематикой, то можно заставить Google искать только страницы, на которых нет определенных слов. Для этого надо указать эти слова, поставив перед каждым знак – без пробела перед словом. Например:
рыбалка -водка
Поиск при помощи знака ~
Возможно, что вы захотите найти не только указанное слово, но также и его синонимы. Для этого перед словом укажите символ ~.
Поиск точной фразы при помощи двойных кавычек
Google ищет на каждой странице все вхождения слов, которые вы написали в строке запроса, причем ему неважно взаимное расположение слов, главное чтобы все указанные слова были на странице одновременно (это действие по умолчанию). Чтобы найти точную фразу – ее нужно взять в кавычки. Например:
"подставка для книг"
Чтобы было хоть одно из указанных слов нужно указать логическую операцию явно: OR. Например:
книга безопасность OR защита
Кроме того в строке поиска можно использовать знак * для обозначения любого слова и. для обозначения любого символа.
Поиск слов при помощи дополнительных операторов
Существуют поисковые операторы, которые указываются в строке поиска в формате:
operator:search_term
Пробелы рядом с двоеточием не нужны. Если вы вставите пробел после двоеточия, то увидите сообщение об ошибке, а перед ним, то Google будет использовать их как обычную строку для поиска.
Существуют группы дополнительных операторов поиска: языки - указывают на каком языке вы хотите увидеть результат, дата - ограничивают результаты за прошедшие три, шесть или 12 месяцев, вхождения - указывают в каком месте документа нужно искать строку: везде, в заголовке, в URL, домены - производить поиск по указанному сайту или наоборот исключить его из поиска, безопасный поиск - блокируют сайты содержащие указанный тип информации и удаляют их со страниц результатов поиска.
При этом некоторые операторы не нуждаются в дополнительном параметре, например запрос "cache:www.google.com
" может быть вызван, как полноценная строка для поиска, а некоторые ключевые слова, наоборот, требуют наличия слова для поиска, например " site:www.google.com help
". В свете нашей тематики посмотрим на следующие операторы:
Оператор |
Описание |
Требует дополнительного параметра? |
поиск только по указанному в search_term сайту |
||
поиск только в документах с типом search_term |
||
найти страницы, содержащие search_term в заголовке |
||
найти страницы, содержащие все слова search_term в заголовке |
||
найти страницы, содержащие слово search_term в своем адресе |
||
найти страницы, содержащие все слова search_term в своем адресе |
Оператор site: ограничивает поиск только по указанному сайту, причем можно указать не только доменное имя, но и IP адрес. Например, введите:
Оператор filetype: ограничивает поиск в файлах определенного типа. Например:
На дату выхода статьи Googlе может искать внутри 13 различных форматов файлов:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Rich Text Format (rtf)
- Shockwave Flash (swf)
- Text (ans, txt)
Оператор link:
показывает все страницы, которые указывают на указанную страницу.
Наверно всегда интересно посмотреть, как много мест в Интернете знают о тебе. Пробуем:
Оператор cache: показывает версию сайта в кеше Google, как она выглядела, когда Google последний раз посещал эту страницу. Берем любой, часто меняющийся сайт и смотрим:
Оператор intitle: ищет указанное слово в заголовке страницы. Оператор allintitle: является расширением – он ищет все указанные несколько слов в заголовке страницы. Сравните:
intitle:полет на марс
intitle:полет intitle:на intitle:марс
allintitle:полет на марс
Оператор inurl: заставляет Google показать все страницы содержащие в URL указанную строку. Оператор allinurl: ищет все слова в URL. Например:
allinurl:acid acid_stat_alerts.php
Эта команда особенно полезна для тех, у кого нет SNORT – хоть смогут посмотреть, как он работает на реальной системе.
Методы взлома при помощи Google
Итак, мы выяснили что, используя комбинацию вышеперечисленных операторов и ключевых слов, любой человек может заняться сбором нужной информации и поиском уязвимостей. Эти технические приемы часто называют Google Hacking.
Карта сайта
Можно использовать оператор site: для просмотра всех ссылок, которые Google нашел на сайте. Обычно страницы, которые динамически создаются скриптами, при помощи параметров не индексируются, поэтому некоторые сайты используют ISAPI фильтры, чтобы ссылки были не в виде /article.asp?num=10&dst=5 , а со слешами /article/abc/num/10/dst/5 . Это сделано для того, чтобы сайт вообще индексировался поисковиками.
Попробуем:
site:www.whitehouse.gov whitehouse
Google думает, что каждая страница сайта содержит слово whitehouse. Этим мы и пользуемся, чтобы получить все страницы.
Есть и упрощенный вариант:
site:whitehouse.gov
И что самое приятное - товарищи с whitehouse.gov даже не узнали, что мы посмотрели на структуру их сайта и даже заглянули в кэшированные странички, которые скачал себе Google. Это может быть использовано для изучения структуры сайтов и просмотра содержимого, оставаясь незамеченным до поры до времени.
Просмотр списка файлов в директориях
WEB серверы могут показывать списки директорий сервера вместо обычных HTML страниц. Обычно это делается для того, чтобы пользователи выбирали и скачивали определенные файлы. Однако во многих случаях у администраторов нет цели показать содержимое директории. Это возникает вследствие неправильной конфигурации сервера или отсутствия главной страницы в директории. В результате у хакера появляется шанс найти что-нибудь интересное в директории и воспользоваться этим для своих целей. Чтобы найти все такие страницы, достаточно заметить, что все они содержат в своем заголовке слова: index of. Но поскольку слова index of содержат не только такие страницы, то нужно уточнить запрос и учесть ключевые слова на самой странице, поэтому нам подойдут запросы вида:
intitle:index.of parent directory
intitle:index.of name size
Поскольку в основном листинги директорий сделаны намеренно, то вам, возможно, трудно будет найти ошибочно выведенные листинги с первого раза. Но, по крайней мере, вы уже сможете использовать листинги для определения версии WEB сервера, как описано ниже.
Получение версии WEB сервера.
Знание версии WEB сервера всегда полезно перед началом любой атака хакера. Опять же благодаря Google можно получить эту информацию без подключения к серверу. Если внимательно посмотреть на листинг директории, то можно увидеть, что там выводится имя WEB сервера и его версия.
Apache1.3.29 - ProXad Server at trf296.free.fr Port 80
Опытный администратор может подменить эту информацию, но, как правило, она соответствует истине. Таким образом, чтобы получить эту информацию достаточно послать запрос:
intitle:index.of server.at
Чтобы получить информацию для конкретного сервера уточняем запрос:
intitle:index.of server.at site:ibm.com
Или наоборот ищем сервера работающие на определенной версии сервера:
intitle:index.of Apache/2.0.40 Server at
Эта техника может быть использована хакером для поиска жертвы. Если у него, к примеру, есть эксплойт для определенной версии WEB сервера, то он может найти его и попробовать имеющийся эксплойт.
Также можно получить версию сервера, просматривая страницы, которые по умолчанию устанавливаются при установке свежей версии WEB сервера. Например, чтобы увидеть тестовую страницу Apache 1.2.6 достаточно набрать
intitle:Test.Page.for.Apache it.worked!
Мало того, некоторые операционные системы при установке сразу ставят и запускают WEB сервер. При этом некоторые пользователи даже об этом не подозревают. Естественно если вы увидите, что кто-то не удалил страницу по умолчанию, то логично предположить, что компьютер вообще не подвергался какой-либо настройке и, вероятно, уязвим для атак.
Попробуйте найти страницы IIS 5.0
allintitle:Welcome to Windows 2000 Internet Services
В случае с IIS можно определить не только версию сервера, но и версию Windows и Service Pack.
Еще одним способом определения версии WEB сервера является поиск руководств (страниц подсказок) и примеров, которые могут быть установлены на сайте по умолчанию. Хакеры нашли достаточно много способов использовать эти компоненты, чтобы получить привилегированный доступ к сайту. Именно поэтому нужно на боевом сайте удалить эти компоненты. Не говоря уже о том, что по наличию этих компонентов можно получить информацию о типе сервера и его версии. Например, найдем руководство по apache:
inurl:manual apache directives modules
Использование Google как CGI сканера.
CGI сканер или WEB сканер – утилита для поиска уязвимых скриптов и программ на сервере жертвы. Эти утилиты должны знать что искать, для этого у них есть целый список уязвимых файлов, например:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Мы может найти каждый из этих файлов с помощью Google, используя дополнительно с именем файла в строке поиска слова index of или inurl: мы можем найти сайты с уязвимыми скриптами, например:
allinurl:/random_banner/index.cgi
Пользуясь дополнительными знаниями, хакер может использовать уязвимость скрипта и с помощью этой уязвимости заставить скрипт выдать любой файл, хранящийся на сервере. Например файл паролей.
Как защитить себя от взлома через Google.
1. Не выкладывайте важные данные на WEB сервер.
Даже если вы выложили данные временно, то вы можете забыть об этом или кто-то успеет найти и забрать эти данные пока вы их не стерли. Не делайте так. Есть много других способов передачи данных, защищающих их от кражи.
2. Проверьте свой сайт.
Используйте описанные методы, для исследования своего сайта. Проверяйте периодически свой сайт новыми методами, которые появляются на сайте http://johnny.ihackstuff.com . Помните, что если вы хотите автоматизировать свои действия, то нужно получить специальное разрешение от Google. Если внимательно прочитать http://www.google.com/terms_of_service.html , то вы увидите фразу: You may not send automated queries of any sort to Google"s system without express permission in advance from Google.
3. Возможно, вам не нужно чтобы Google индексировал ваш сайт или его часть.
Google позволяет удалить ссылку на свой сайт или его часть из своей базы, а также удалить страницы из кэша. Кроме того вы можете запретить поиск изображений на вашем сайте, запретить показывать короткие фрагменты страниц в результатах поиска Все возможности по удалению сайта описаны на сранице http://www.google.com/remove.html . Для этого вы должны подтвердить, что вы действительно владелец этого сайта или вставить на страницу теги или
4. Используйте robots.txt
Известно, что поисковые машины заглядывают в файл robots.txt лежащий в корне сайта и не индексируют те части, которые помечены словом Disallow . Вы можете воспользоваться этим, для того чтобы часть сайта не индексировалась. Например, чтобы не индексировался весь сайт, создайте файл robots.txt содержащий две строчки:
User-agent: *
Disallow: /
Что еще бывает
Чтобы жизнь вам медом не казалась, скажу напоследок, что существуют сайты, которые следят за теми людьми, которые, используя вышеизложенные выше методы, разыскивают дыры в скриптах и WEB серверах. Примером такой страницы является
Приложение.
Немного сладкого. Попробуйте сами что-нибудь из следующего списка:
1. #mysql dump filetype:sql - поиск дампов баз данных mySQL
2. Host Vulnerability Summary Report - покажет вам какие уязвимости нашли другие люди
3. phpMyAdmin running on inurl:main.php - это заставит закрыть управление через панель phpmyadmin
4. not for distribution confidential
5. Request Details Control Tree Server Variables
6. Running in Child mode
7. This report was generated by WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – может кому нужны кофигурационные файлы файрволов? :)
10. intitle:index.of finances.xls – мда....
11. intitle:Index of dbconvert.exe chats – логи icq чата
12. intext:Tobias Oetiker traffic analysis
13. intitle:Usage Statistics for Generated by Webalizer
14. intitle:statistics of advanced web statistics
15. intitle:index.of ws_ftp.ini – конфиг ws ftp
16. inurl:ipsec.secrets holds shared secrets – секретный ключ – хорошая находка
17. inurl:main.php Welcome to phpMyAdmin
18. inurl:server-info Apache Server Information
19. site:edu admin grades
20. ORA-00921: unexpected end of SQL command – получаем пути
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25. inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
Учебный центр "Информзащита" http://www.itsecurity.ru - ведущий специализированный центр в области обучения информационной безопасности (Лицензия Московского Комитета образования № 015470, Государственная аккредитация № 004251). Единственный авторизованный учебный центр компаний Internet Security Systems и Clearswift на территории России и стран СНГ. Авторизованный учебный центр компании Microsoft (специализация Security). Программы обучения согласованы с Гостехкомиссией России, ФСБ (ФАПСИ). Свидетельства об обучении и государственные документы о повышении квалификации.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе, различные скидки от магазина и производителей ПО.
Для любой компании важно защищать конфиденциальные данные. Утечка клиентских логинов и паролей или потеря системных файлов, размещенных на сервере, может не только повлечь за собой финансовые убытки, но и уничтожить репутацию самой, казалось бы, надежной организации. Автор статьи — Вадим Кулиш .
Учитывая все возможные риски, компании внедряют новейшие технологии и тратят огромные средства, пытаясь предотвратить несанкционированный доступ к ценным данным.
Однако задумывались ли вы, что помимо сложных и хорошо продуманных хакерских атак, существуют простые способы обнаружить файлы
, которые не были надежно защищены. Речь идет об операторах поиска — словах, добавляемых к поисковым запросам для получения более точных результатов. Но обо все по порядку.
Серфинг в Интернете невозможно представить без таких поисковых систем как Google, Yandex, Bing и других сервисов подобного рода. Поисковик индексируют множество сайтов в сети. Делают они это с помощью поисковых роботов, которые обрабатывают большое количество данных и делают их доступными для поиска.
Популярные операторы поисковых запросов Google
Использование следующих операторов позволяет сделать процесс поиска необходимой информации более точным:
* site: ограничивает поиск определенным ресурсом
Пример: запрос site:example.com найдет всю информацию, которую содержит Google для сайта example.com.
* filetype: позволяет искать информацию в определенном типе файлов
Пример: запрос покажет весь список файлов на сайте, которые присутствуют в поисковике Google.
* inurl: — поиск в URL ресурса
Пример: запрос site:example.com inurl:admin — ищет панель администрирования на сайте.
* intitle: — поиск в названии страницы
Пример: запрос site: example.com intitle:»Index of» — ищет страницы на сайте example.com со списком файлов внутри
* cache: — поиск в кэше Google
Пример: запрос cache:example.com вернет все закэшированные в системе страницы ресурса example.com
К сожалению, поисковые роботы не умеют определять тип и степень конфиденциальности информации. Поэтому они одинаково обрабатывают статью из блога, которая рассчитана на широкий круг читателей, и резервную копию базы данных, которая хранится в корневой директории веб-сервера и не подлежит использованию посторонними лицами.
Благодаря этой особенности, а также используя операторы поиска, злоумышленникам и удается обнаружить уязвимости веб-ресурсов, различные утечки информации (резервные копии и текст ошибок работы веб-приложения), скрытые ресурсы, такие как открытые панели администрирования, без механизмов аутентификации и авторизации.
Какие конфиденциальные данные могут быть найдены в сети?
Следует иметь в виду, что информация, которая может быть обнаружена поисковыми системами и потенциально может быть интересна хакерам, включает в себя:
* Домены третьего уровня исследуемого ресурса
Домены третьего уровня можно обнаружить с помощью слова «site:». К примеру, запрос вида site:*.example.com выведет все домены 3-го уровня для example.com. Такие запросы позволяют обнаружить скрытые ресурсы администрирования, системы контроля версий и сборки, а также другие приложения, имеющие веб-интерфейс.
* Скрытые файлы на сервере
В поисковую выдачу могут попасть различные части веб-приложения. Для их поиска можно воспользоваться запросом filetype:php site:example.com . Это позволяет обнаружить ранее недоступную функциональность в приложении, а также различную информацию о работе приложения.
Для поиска резервных копий используется ключевое слово filetype:. Для хранения резервных копий используются различные расширения файлов, но чаще всего используются расширения bak, tar.gz, sql. Пример запроса: site:*.example.com filetype:sql . Резервные копии часто содержат логины и пароли от административных интерфейсов, а также данные пользователей и исходный код веб-сайта.
* Ошибки работы веб-приложения
Текст ошибки может включать в себя различные данные о системных компонентах приложения (веб-сервер, база данных, платформа веб-приложения). Такая информация всегда очень интересна хакерам, так как позволяет получить больше информации об атакуемой системе и усовершенствовать свою атаку на ресурс. Пример запроса: site:example.com «warning» «error» .
* Логины и пароли
В результате взлома веб-приложения в сети Интернет могут появиться данные пользователей этого сервиса. Запрос filetype:txt «login» «password» позволяет найти файлы с логинами и паролями. Таким же образом можно проверить, не взломали ли вашу почту или какой-либо аккаунт. Просто сделайте запрос filetype:txt имя_пользователя_или_электронная_почта» .
Комбинации ключевых слов и строки поиска, используемые для обнаружения конфиденциальной информации, называются Google Dorks.
Специалисты Google собрали их в своей публичной базе данных Google Hacking Database . Это дает возможность представителю компании, будь то CEO, разработчик или вебмастер, выполнить запрос в поисковике и определить, насколько хорошо защищены ценные данные. Все дорки распределены по категориям для облегчения поиска.
Нужна помощь? Закажите консультацию специалистов по тестированию защищенности a1qa.
Как Google Dorks вошли в историю хакерства
Напоследок несколько примеров того, как Google Dorks помогли злоумышленникам получить важную, но ненадежно защищенную информацию:
Пример из практики №1. Утечка конфиденциальных документов на сайте банка
В рамках анализа защищенности официального сайта банка было обнаружено огромное количество pdf-документов. Все документы были обнаружены с помощью запроса «site:bank-site filetype:pdf». Интересным оказалось содержимое документов, так как там были планы помещений, в которых располагались отделения банка по всей стране. Это информация была бы очень интересна грабителям банков.
Пример из практики №2. Поиск данных платежных карт
Очень часто при взломе интернет-магазинов злоумышленники получают доступ к данным платежных карт пользователей. Для организации совместного доступа к этим данным злоумышленники используют публичные сервисы, которые индексируются Google. Пример запроса: «Card Number» «Expiration Date» «Card Type» filetype:txt.
Однако не стоит ограничиваться базовыми проверками. Доверьте комплексную оценку вашего продукта a1qa. Ведь хищение данных дешевле предотвратить, чем устранять последствия.
Получение частных данных не всегда означает взлом - иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного - от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто - нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, - например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй - расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет - результаты в большинстве случаев выходят одинаковые.

Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor - в тексте, снабженном тегом , allintitle - в заголовках страниц, allintext - в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl - только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу - site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
Allintext: card number expiration date /2017 cvv

Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум - поле «адрес». Проверить все эти предположения проще простого.

Inurl:nasa.gov filetype:xlsx "address"

Пользуемся бюрократией
Подобные находки - приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B - предназначенные только для внутреннего использования, C - строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня.mil, выделенного для армии США.
"DISTRIBUTION STATEMENT C" inurl:navy.mil

Очень удобно, что в домене.mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки - говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах.ru и.рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»).

Внимательно изучив любой документ с сайта в домене.mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
Allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов. Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.

Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.

Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса .

Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением.inc. Искать их можно следующим образом:
"pwd=" "UID=" ext:inc
Раскрываем пароли от СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш - пароль.

До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
Intext:DB_PASSWORD filetype:env

С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
Filetype:reg HKEY_CURRENT_USER "Password"=
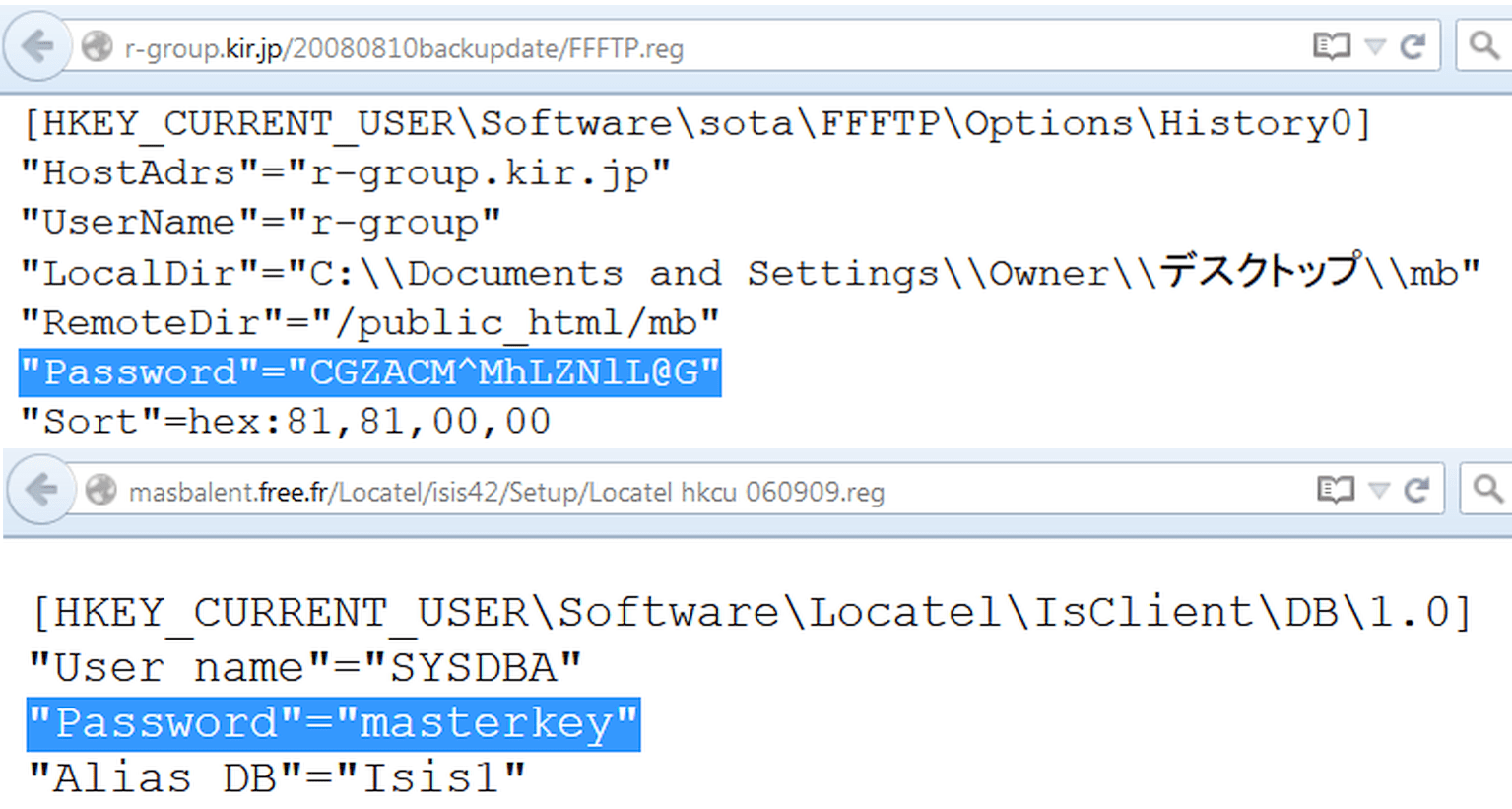
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант - найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
Filetype:xls inurl:password

С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.

Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.

Следим за обновлениями
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w - за неделю, d - за прошедший день, h - за последний час, n - за минуту, а s - за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат .
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск - gcs=Bobruisk . В разделе для разработчиков можно найти полный список .
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов - NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Intitle:"Index of /Personal/" -names -tutorial -banking
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN - штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
Filetype:pcf vpn OR Group

INFO
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через thecampusgeeks.com .
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!